
All about APX JMPABS
Why do we need JMPABS?
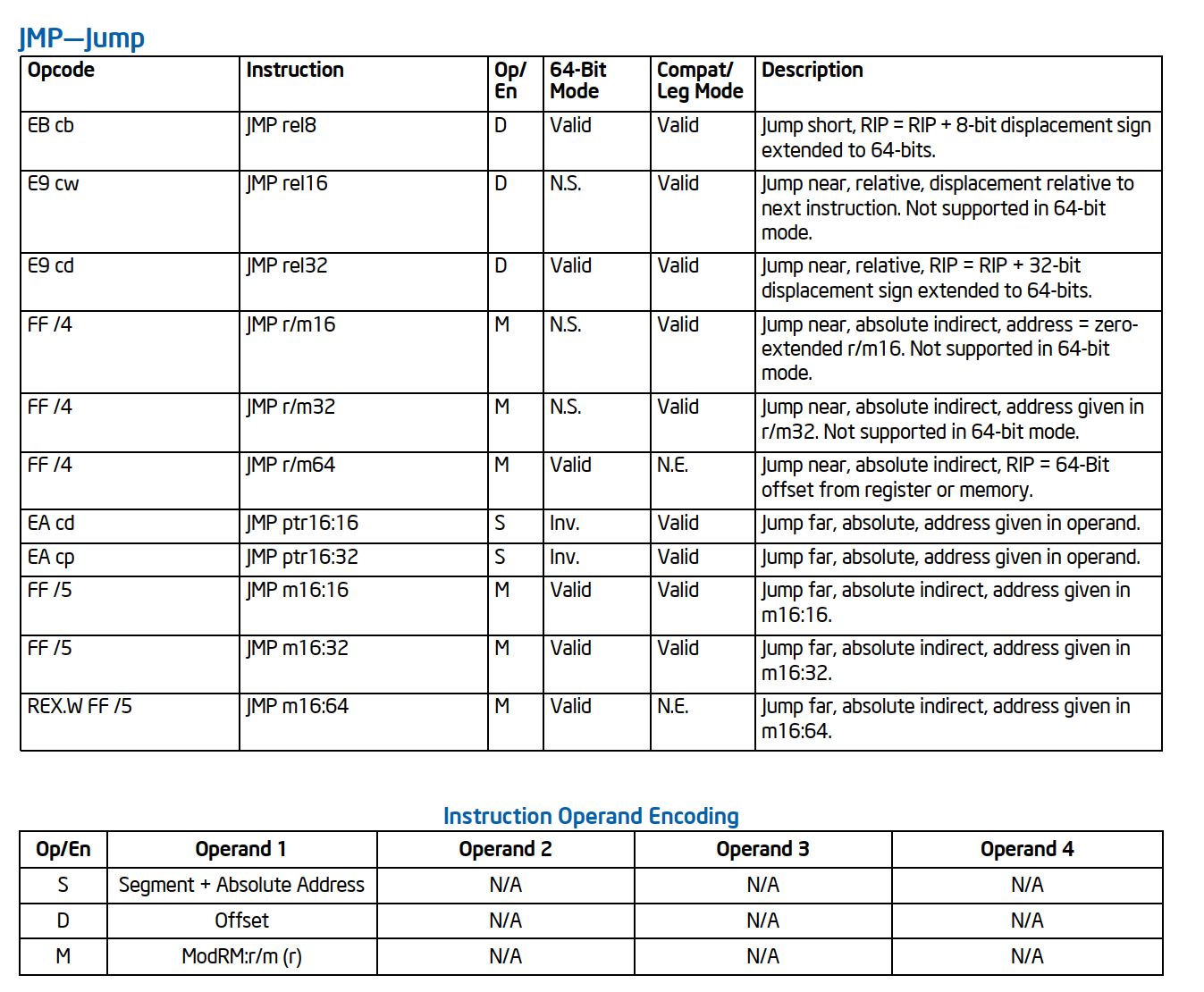
JMPABS, which, as the name already suggests, allows jumping to a 64-bit absolute address. Before APX, X86 has 32-bit displacement limitations for all direct branches.
# jmp-1.s
.text
foo:
.zero 0x7ffffffb
jmp foo
$ as jmp-1.s -o jmp-1.o
$ objdump -d jmp-1.o --start-address=0x7ffffffb
Disassembly of section .text:
000000007ffffffb <foo+0x7ffffffb>:
7ffffffb: e9 00 00 00 80 jmpq 0 <foo>
The JMP instruction here corresponds to JMP rel32 in the above table, where rel32 is equal to 0x8fffffff (-2^31).
And if we pad one more zero between the symbol foo and the JMP instruction
# jmp-2.s
.text
foo:
.zero 0x7ffffffc
jmp foo
the assembler will report an error
$ as jmp-2.s -o jmp-2.o
jmp-2.s: Assembler messages:
jmp-2.s:4: Error: jump target out of range
In order to jump “anywhere”, compiler will fallback to indirect branches when the displacement can not fit in a 32-bit immediate, e.g.
# jmp-3.s
.text
foo:
.zero 0x7ffffffc
movq foo, %rax
jmp *%rax
This can be seen frequently in code generated/used by dynamic linkers for PLT (Program Linkage Table) and in JIT(Just-In-Time) compiler.
However, indirect branches have some downsides
1. Less-than-ideal prediction behaviour
In computer architecture, a branch predictor is a digital circuit that tries to guess which way a branch (e.g., an if–then–else structure) will go before this is known definitively. The purpose of the branch predictor is to improve the flow in the instruction pipeline. Branch predictors play a critical role in achieving high performance in many modern pipelined microprocessor architectures.
As we can see in intel-optimization-manual, Intel CPU does have a branch predictor
Indirect branches are more likely to be mispredicted than direct branches, thus bringing more bad speculation.
2. Less-than-ideal security behavior
It can potentially be exploited via JOP(Jump-Oriented Programming), or indirect side-channel behavior.
3. Less-than-ideal power consumption
Direct branches consumes less power than indirect branches.
What does JMPABS look like?
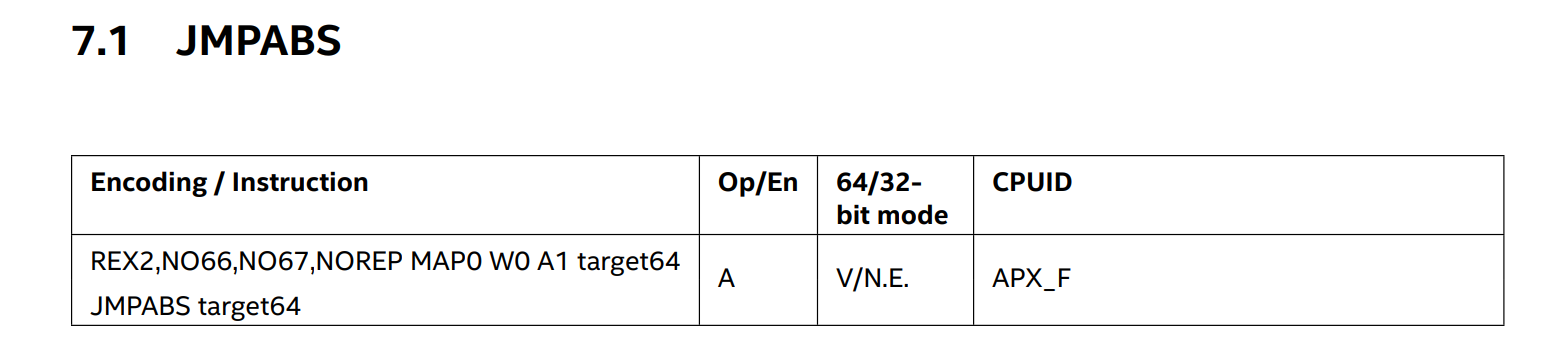
- JMPABS is a 64-bit only ISA extension, and acts as a near-direct branch with an absolute target. The 64-bit immediate operand is treated an as absolute effective address, which is subject to canonicality checks.
- JMPABS is in legacy map 0 and requires
REX2prefix withREX2.M0=0andREX2.W=0. All other REX2 payload bits are ignored. There is a breif introduction toREX2here. - Prefixing JMPABS with 0x66, 0x67, repeat prefix(0xF2/0xF3)triggers
#UD. Segment overrides are allowed but ignored by JMPABS. - JMPABS is a direct, un-conditional jump, and will be treated as such from the perspective of both Intel® Perfmon and Last Branch Record (LBR) facilities. JMPABS does have unique treatment from an Intel® Processor Trace perspective in that it is designed to emit an Intel® Processor Trace TIP packet by default (unlike other direct, un-conditional jumps).
Where will JMPABS be used?
JIT optimization
Replace indirects/trampolines from JIT’ed routines to runtime with JMPABS.
Compiler usages
None currently. Static compilation units rarely reach a size necessitating control flow with large displacements. For most of prgrams, we are in small code model: the program and its symbols must be linked in the lower 2 GB of the address space. Pointers are 64 bits.
PLT Optimization
In X86 relocation, I mentioned how Procedure Linkage Table (PLT) is used to provide the indirection and how lazy binding works.
In addition to lazy binding, there is another way to resolve a function address called eager binding. You can find detailed introduction at MaskRay’s blog all about procedure linkage table. In a sentence, when ld.so use eager binding, it transfers control to the component, during relocation resolving, ld.so resolves the address of symbol and writes it into the .got.plt entry. Therefore, when the program runs, the .got.plt entry is guaranteed to hold the address of the target function.
// e.c
int foo();
int bar() { return foo(); }
$ gcc -fPIC -shared -o libe.so e.c
$ objdump -d libe.so
0000000000001030 <foo@plt>:
1030: ff 25 e2 2f 00 00 jmpq *0x2fe2(%rip) # 4018 <foo>
1036: 68 00 00 00 00 pushq $0x0
103b: e9 e0 ff ff ff jmpq 1020 <.plt>
0000000000001109 <bar>:
1109: 55 push %rbp
110a: 48 89 e5 mov %rsp,%rbp
110d: b8 00 00 00 00 mov $0x0,%eax
1112: e8 19 ff ff ff callq 1030 <foo@plt>
1117: 5d pop %rbp
1118: c3 retq
To put it simple, the R_X86_64_JUMP_SLOT referenced by 0x2fe2(%rip) is already filled by the address of foo before the program runs.
When eager binding is used and SELinux is not enabled, ld.so can replace indirect JMP *m with JMPABS. Applications benefit from being re-loaded (with updated dynamic linker). No need to re-compile.
The instruction sequence
1030: ff 25 e2 2f 00 00 jmpq *0x2fe2(%rip) # 4018 <foo>
1036: 68 00 00 00 00 pushq $0x0
103b: e9 e0 ff ff ff jmpq 1020 <.plt>
will be rewritten to
1030: jmpabs <absolute address of foo>
103b: jmpq 1020 <.plt>
Since the rewrite changes the first branch instruction length from 6 to 11, so the PUSHQ is destroyed. But it doesn’t matter b/c it’s never executed when eager binding is used. Becasue Neither the JMP *m nor JMPABS changes stack pointer RSP, the GDB stack trace is same as before.
HJ proposed the design here for this optimization.
Three optional dynamic array tags are added.
| Name | Meaning |
|---|---|
| DT_X86_64_PLT | The address of the procedure linkage table |
| DT_X86_64_PLTSZ | The total size, in bytes, of the procedure linkage table |
| DT_X86_64_PLTENT | The size, in bytes, of a procedure linkage table entry |
ld.so is the producer of these tags and glibc is the user.
If permitted, using DT_X86_64_PLT, DT_X86_64_PLTSZ and DT_X86_64_PLTENT together with the r_offset and r_addend fields of R_X86_64_JUMP_SLOT relocation, the dynamic linker (ld.so) may retrieve the indirect branch target address stored at the global offset table entry and rewrite indirect branch in the procedure linkage table entry to direct branch.
glibc needs to change the PLT section to writable before rewrite and cahnge it to read-only after rewrite.
LLVM run-time dynamic linker may need similar change as ld.so.
Reference
- https://groups.google.com/g/x86-64-abi/c/Gy0RmoP2LnE
- https://www.intel.com/content/www/us/en/developer/articles/technical/advanced-performance-extensions-apx.html
- https://maskray.me/blog/2021-09-19-all-about-procedure-linkage-table
- https://www.intel.com/content/www/us/en/developer/articles/technical/intel-sdm.html