
All about APX conditional ISA
Motivation
Somtimes branch mispredictions are a major performance limiter in workloads. The bottleneck is data-dependent conditional branches and hard to mitigate in hardware alone. Intel introduced basic conditional ISA CMOV with P6 in 1996. CMOV, as the name suggests, is conditional move and its operation is
temp := SRC
IF condition TRUE
THEN DEST := temp;
ELSE IF (OperandSize = 32 and IA-32e mode active)
THEN DEST[63:32] := 0;
FI;
It’s widely used, but scope is limited to very simple conditionals, e.g.
// a.c
int f(int x, int y, int z) { return x ? y : z; }
$ clang -O2 a.c -S -march=i386 -m32 -o -
f:
movl 12(%esp), %eax
movl 4(%esp), %edx
testl %edx, %edx
je .L2
movl 8(%esp), %eax
.L2:
ret
$ clang -O2 a.c -S -march=i386 -m32 -msse -o -
f:
movl 12(%esp), %eax
movl 4(%esp), %edx
testl %edx, %edx
cmovne 8(%esp), %eax
ret
NOTE: SSE implies CMOV for X86.
Intel® APX introduces new conditonal ISA to allow the compiler to do more conditional operations other than MOV to elminate the conditional branches, as a result, reducing the branch mispredictions.
New conditional instructions (NCI)
Conditional loads and stores
Encoding and operation
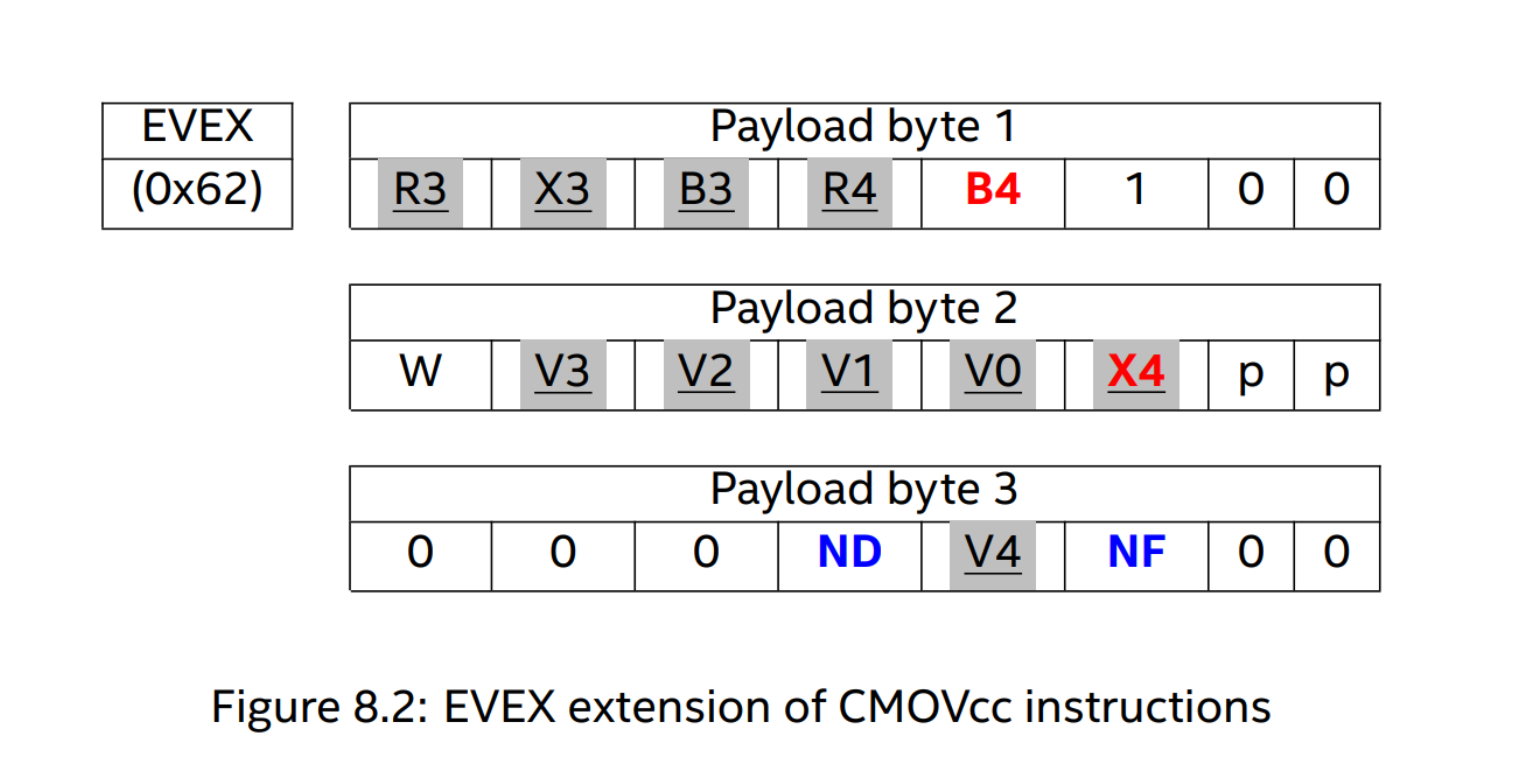
Intel® APX introduces four different forms of EVEX-promoted CMOV instructions corresponding to the four possible combinations of the values of EVEX.ND and EVEX.NF. Three of these forms have a new mnemonic, CFCMOV, where the CF prefix denotes “conditional faulting” and means that all memory faults are suppressed when the condition code evaluates to false and the r/m operand is a memory operand. Note that EVEX.NF is used as a direction bit in the 2-operand case to reverse the source and destination operands.
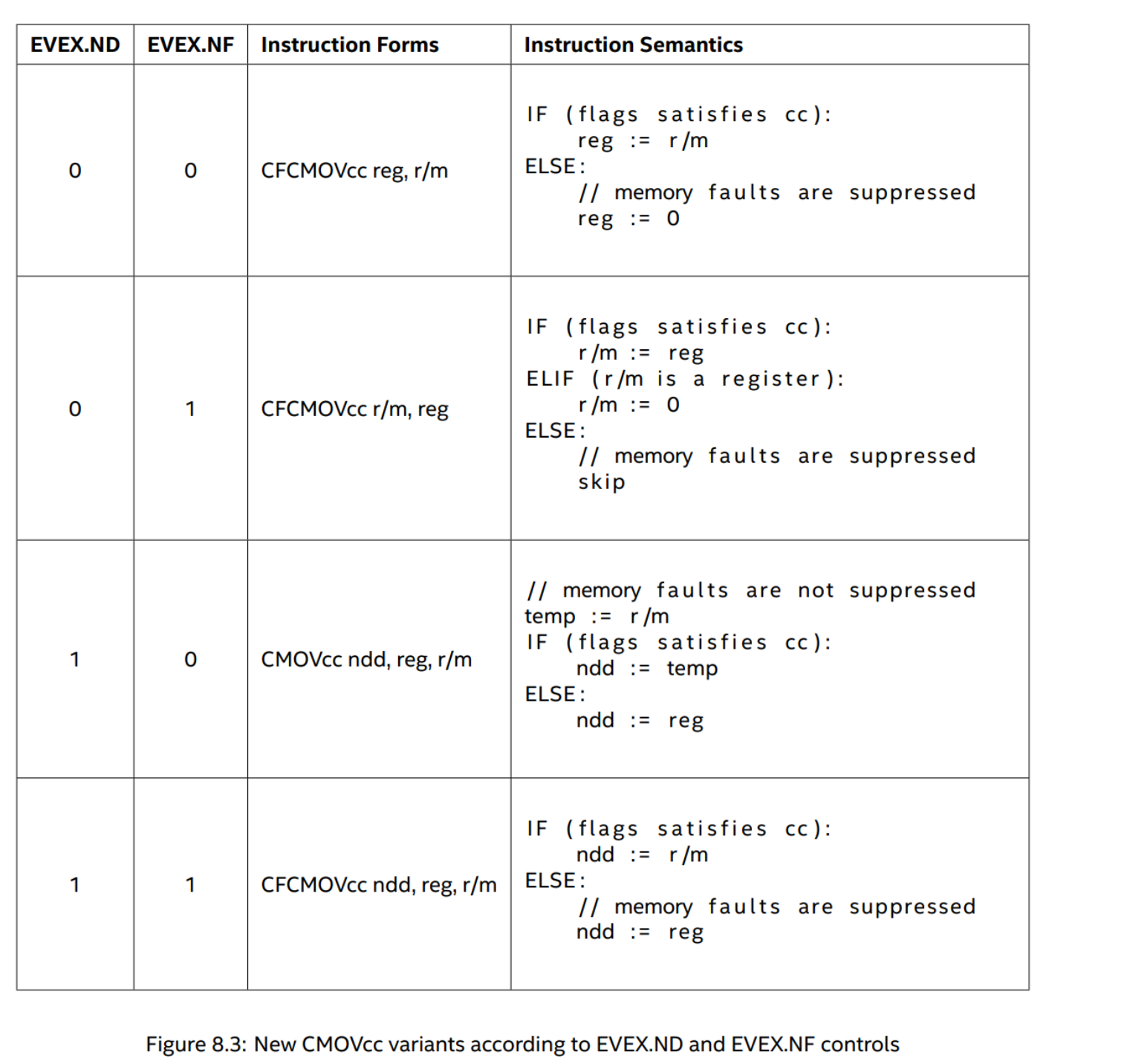
In the above table, r/m refers to the operand encoded in RM, which can be a register or a memory.
Strictly speaking,
- the 3rd format is just a NDD(New data destination) variant of
CMOV - when r/m is a memory operand, the 1st and 4th forms are conditional loads and the 2nd forms are conditional store
- when r/m is a register operand, the 1st form is a zeroing reg2reg CMOV, the 4th form is the reverse encoding of NDD
CMOV, the 2nd is the reverse encoding of the 1st form.
Simple example for usage
// b.c
void f(int *p, int *q, int n) {
if (*p > n)
*p = *q;
return;
}
Without conditional load/store, the assembly looks like
$ clang -S -O2 b.c -o -
f:
cmpl %edx, (%rdi)
jle .L1
movl (%rsi), %eax
movl %eax, (%rdi)
.L1:
ret
If conditional load/store is available, we can generate code like
f:
cmpl %edx, (%rdi)
cfcmovgl (%rsi), %eax
cfcmovgl %eax, (%rdi)
ret
Conditional compares
Encoding and operation

Intel® APX introduces CCMPscc and CTESTscc, which are two new sets of instructions for conditional CMP and TEST, respectively. They are encoded by promoting all opcodes of CMP and TEST, except for those forms which have no explicit GPR or memory operands, into the EVEX space and re-interpreting the EVEX payload bits as shown in the above figure. The ND bit is required to be set to 0. There are no EVEX versions of CMP and TEST with EVEX.ND = 1.
The four SC* bits form a source condition code SCC = EVEX.[SC3,SC2,SC1,SC0], the encoding of which is the same as that of the existing x86 condition codes (SDM volume 1 appendix B), with two exceptions:
- If SCC = 0b1010 (P), then SCC evaluates to true regardless of the status flags value.
- If SCC = 0b1011 (NP), then SCC evaluates to false regardless of the status flags value.
Consequently, the SCC cannot test the parity flag PF. In the instruction mnemonics, the SCC appears as a suffix of the mnemonic, with T and F denoting the always true/false codes described above.
The SCC is used as a predicate for controlling the conditional execution of the CCMPscc or CTESTscc instruction:
// CCMP or CTEST
IF (src_flags satisfies scc):
dst_flags = compare(src1,src2)
ELSE:
dst_flags = flags(evex.[of,sf,zf,cf]); // DFV
- If
SCCevaluates to true on the status flags, then the CMP or TEST is executed and it updates the status flags normally. Note that theSCC = 0b1010exception case can be used to encode unconditional CMP or TEST as a special case of CCMP or CTEST. -
If
SCCevaluates to false on the status flags, then the CMP or TEST is not executed and instead the status flags are updated using DFV (Default Flags Value) as follows: - OF = EVEX.OF
- SF = EVEX.SF
- ZF = EVEX.ZF
- CF = EVEX.CF
- PF = EVEX.CF
- AF = 0
Unlike the CMOV extensions discussed above, SCC evaluating to false does not suppress memory faults from a memory operand.
Simple example for usage
// c.c
void foo();
void bar(int x, int y) {
if (x == 5 || y == 17)
foo();
}
Without conditional compare, the assembly looks like
$ clang -O2 -S c.c -o -
bar:
cmpl $5, %edi
je .LBB0_3
cmpl $17, %esi
je .LBB0_3
retq
.LBB0_3:
xorl %eax, %eax
jmp foo # TAILCALL
If conditional compare is available, we can generate code like
bar:
cmpl $5, %edi
ccmpnel {zf} $17, %esi
jne .LBB0_1
xorl %eax, %eax
jmp foo # TAILCALL
.LBB0_1:
retq
Optimizations for NCI in compiler
Compiler needs to do some work to automatically generate new conditional instructions and here I will introduce optimizations that may need to be done in LLVM.
SSA CCMP conversion
This pass performs ccmp-conversion on SSA form machine code after determing if it is possible. Heuristics can be used to determine when the conversion is a good idea.
ccmp-formation works on a CFG representing chained conditions, typically from C’s short-circuit || and && operators:
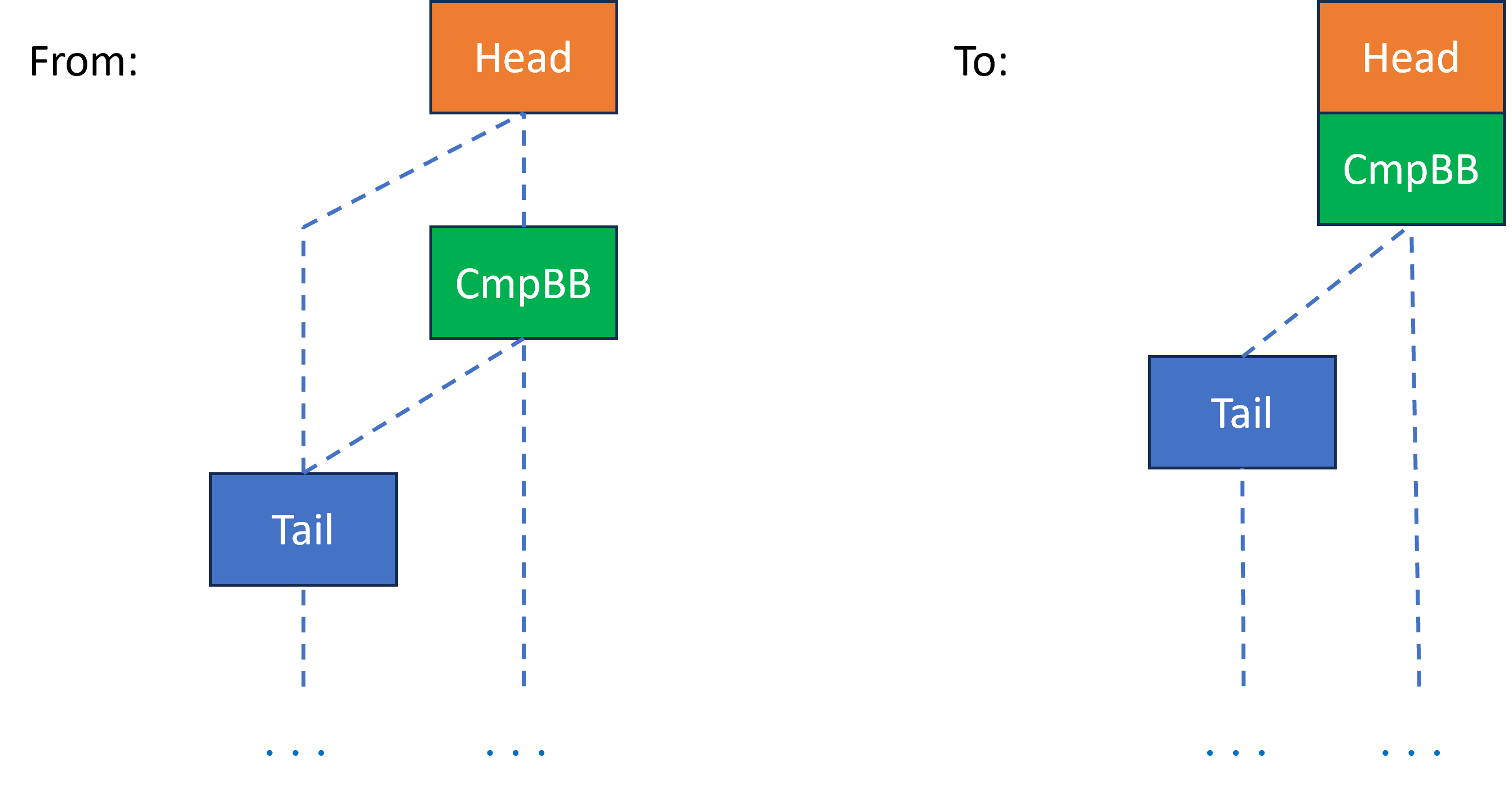
The Head block is terminated by a JCC instruction, and the CmpBB block contains compare + JCC. Tail must be a successor of both. The ccmp-conversion turns the compare instruction in CmpBB into a conditional compare, and merges CmpBB into Head, speculatively executing its instructions. The X86 conditional compare instructions have an operand that specifies the conditional flags to set values when the condition is false and the compare isn’t executed. This makes it possible to chain compares with different condition codes.
Example:
void bar(int x, int y) {
if (a == 5 || b == 17)
foo();
}
Head:
cmpl $5, $edi
je Tail
CmpBB:
cmpl $17, $esi
je Tail
...
Tail:
call foo
Becomes:
Head:
cmpl $5, $edi
ccmpel {zf} $17, $edi
je Tail
...
Tail:
call foo
The ccmp condition code is the one that would cause the Head terminator to branch to CmpBB.
The probabilities of edges needs to updated after the CFG transformation. Assuming the Header that merges CmpBB is calledNewHeader, the other successor of CmpBB is called I, then
P(Tail|NewHeader) = P(Tail|Header) + P(CmpBB|Head) * P(Tail|CmpBB)P(I|NewHeader) = P(CmpBB|Head) * P(I|CmpBB)
where P(X|Y) means probability from Y to X. This is obvious based on the law of total probability, so we won’t go into details.
Early If conversion
This pass performs if-conversion on SSA form machine code after determing if it is possible. Heuristics can be used to determine when the conversion is a good idea.
early-if-conversion works on both triangles and diamonds:
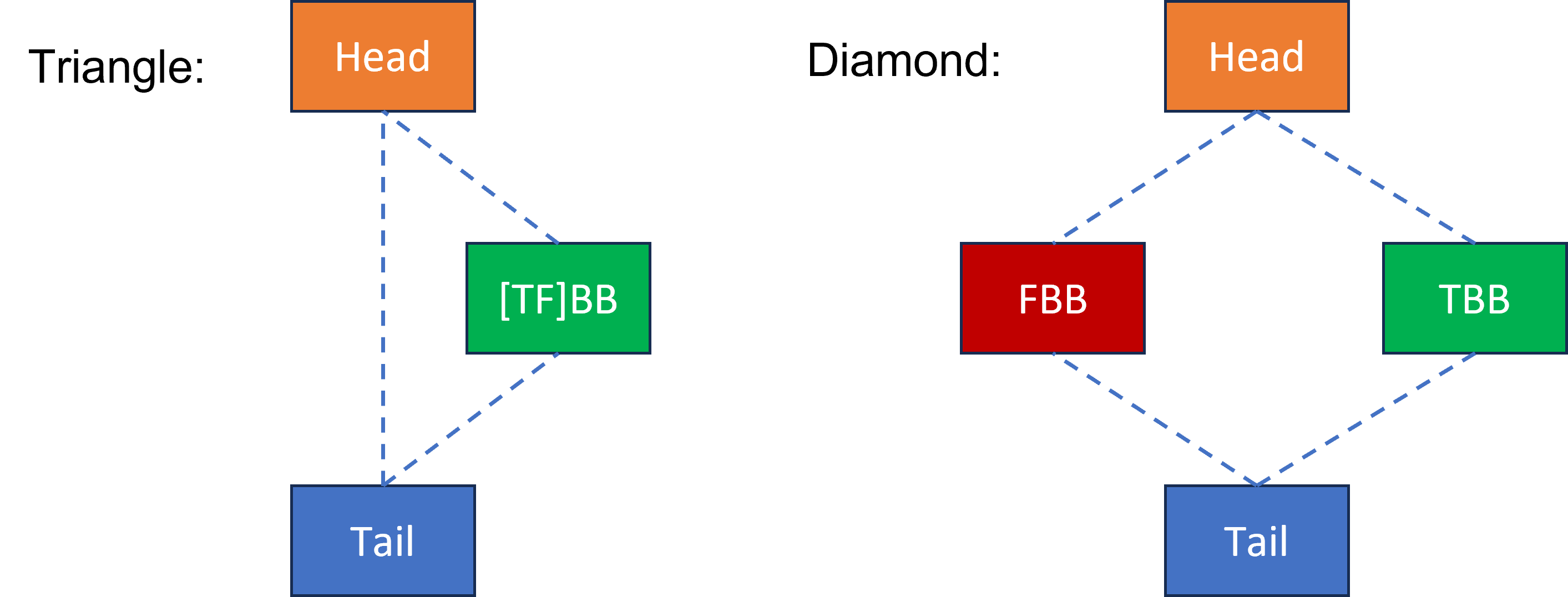
Instructions in the conditional blocks TBB and/or FBB are spliced into the Head block. If all the instructions in TBB and/or FBB are spliced, then the conditional branch in Head can be eliminated.
If we use the word predictable to indicate whether an instruction is a candidate, we use the word predicated to indicate whether it is already a transformed candidate. Then for the APX NCI, they are
| Predictable | Predicated |
|---|---|
| MOV r16, m16 | CFCMOV r16, m16 |
| MOV r32, m32 | CFCMOV r32, m32 |
| MOV r64, m64 | CFCMOV r64, m64 |
| MOV m16, r16 | CFCMOV m16, r16 |
| MOV m32, r32 | CFCMOV m32, r32 |
| MOV m64, r64 | CFCMOV m64, r64 |
Example
void f(int *p, int *q, int n) {
if (*p > n)
*p = *q;
return;
}
Head:
cmpl %edx, (%rdi)
jle Tail
TBB:
movl (%rsi), %eax
movl %eax, (%rdi)
Tail:
ret
Becomes:
Head:
cmpl %edx, (%rdi)
cfcmovgl (%rsi), %eax
cfcmovgl %eax, (%rdi)
Tail:
ret
Peephole optimization
This optimzation for NCI does not eliminate branches, but it reduce redundant store by converting CMOV+STORE to CSTORE (conditional store), e.g.
r1 = LOAD m
CMP
r3 = CMOV r1, r2
STORE r3, m
The above sequence rewrites a value in memory when a condition is satisfied. Without conditional store, we have to write something into memory even if the value is not changed at all.
If conditional store is available, we can tranform the above code to
r1 = LOAD m
CMP
CSTORE r2, m
TODO
In current design, conditional ISA is not fully utilized, so we need a better design.
Conditional ISA Comparison

ARM has conditional simple ALU instructions e.g. CINC, CINV, CNEG.
Reference
- https://www.intel.com/content/www/us/en/developer/articles/technical/intel-sdm.html
- https://www.intel.com/content/www/us/en/developer/articles/technical/advanced-performance-extensions-apx.html